Read: Complex Multimodal Semantics
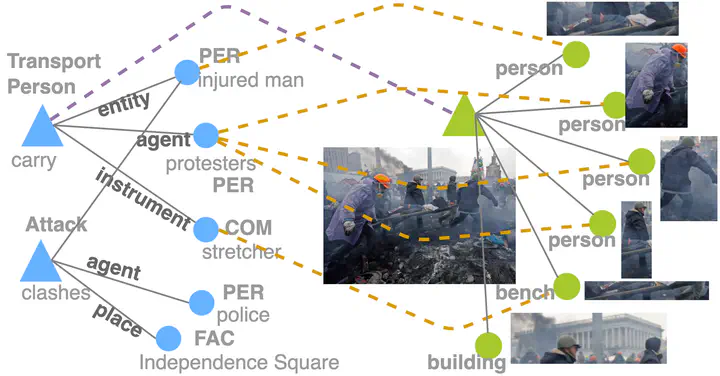 Read: Complex Situation
Read: Complex Situation
Understanding Multimodal Semantic Structures to answer What happened?, Who?, Where?, and When? :
Due to the structural nature and lack of anchoring in a specific image region, abstract semantic structures are difficult to synthesize between text and vision modalities through general large-scale pretraining.
As the first to introduce complex event semantic structures into vision-language pretraining CLIP-Event, I propose a zero-shot cross-modal transfer of semantic understanding abilities from language to vision, which resolves the poor portability issue and supports Zero-shot Multimodal Event Extraction M2E2 for the first time.
I led a 19-student team collaborating with professors from 4 universities to the development of open-source Multimodal IE system GAIA, which was awarded ACL 2020 Best Demo Paper, and ranked 1st in DARPA AIDA TA1 evaluation each phase since 2019.
Our COVID knowledge graph COVID-KG was awarded NAACL 2021 Best Demo Paper; this work was used to generate a drug re-purposing report during collaborations with Prof David Liem from UCLA Data Science in Cardiovascular Medicine; it has also been widely used by other researchers (our extracted knowledge graph COVID-KG has been downloaded more than 2000 times since 2021).