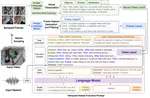
Zhenhailong Wang*, Manling Li*, Ruochen Xu, Luowei Zhou, Jie Lei, Xudong Lin, Shuohang Wang, Ziyi Yang, Chenguang Zhu, Derek Hoiem, Shih-Fu Chang, Mohit Bansal, Heng Ji (* denotes equal contribution)
- Starts a new paradigm of leveraging langauge models to understand videos