Embodied Spatial Reasoning
The list may not be up-to-date. Please find my latest publications on Google Scholar.

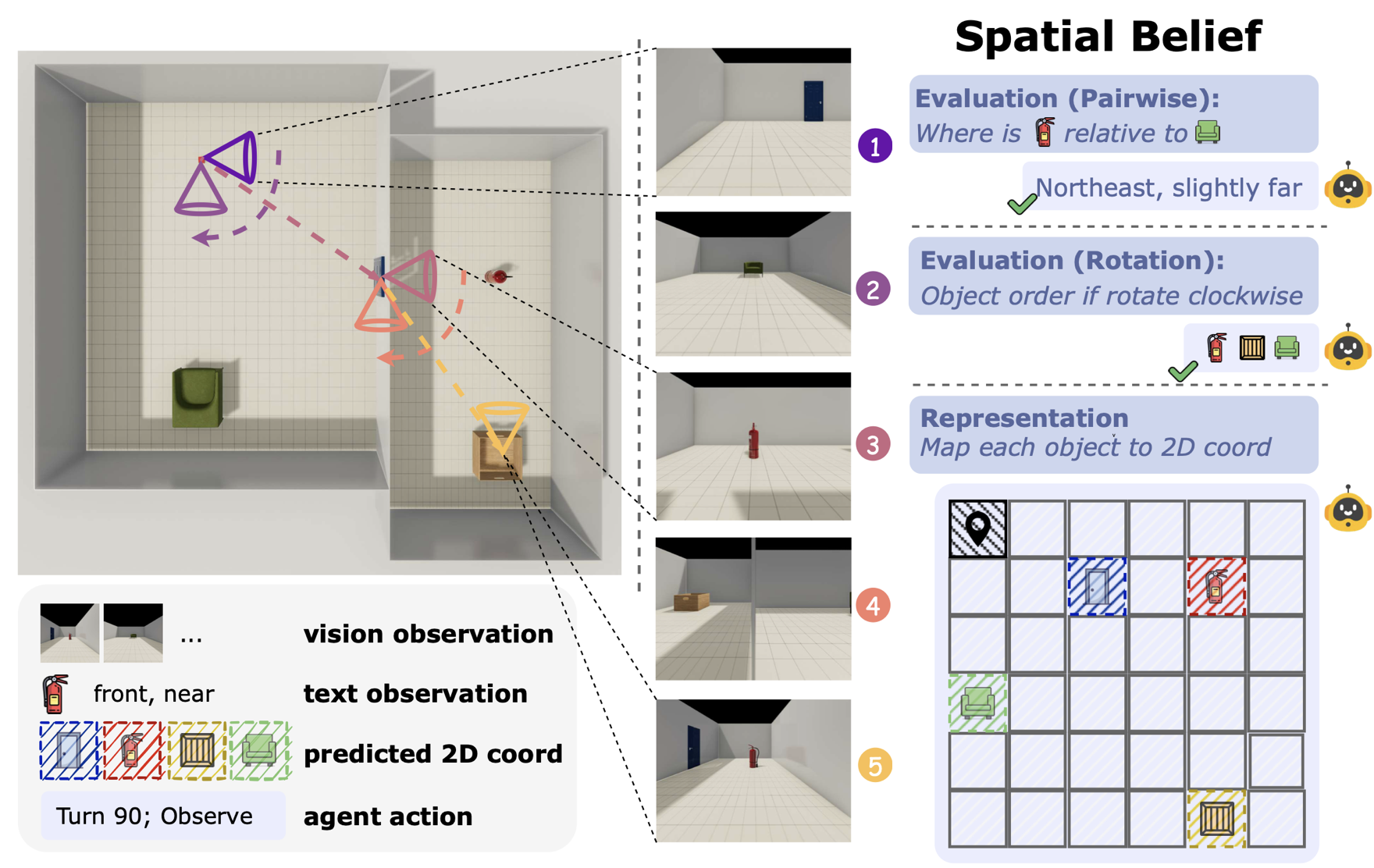
Theory of Space: Can Foundation Models Construct Spatial Beliefs Through Active Perception? [Website][PDF][Data][Code]
Pingyue Zhang*, Zihan Huang*, Yue Wang *, Jieyu Zhang*, Letian Xue, Zihan Wang, Qineng Wang, Keshigeyan Chandrasegaran, Yejin Choi, Ranjay Krishna, Ruohan Zhang, Jiajun Wu, Li Fei-Fei, Manling Li
ICLR 2026
Featured by MIT Tech Review China, Stanford AI Blog

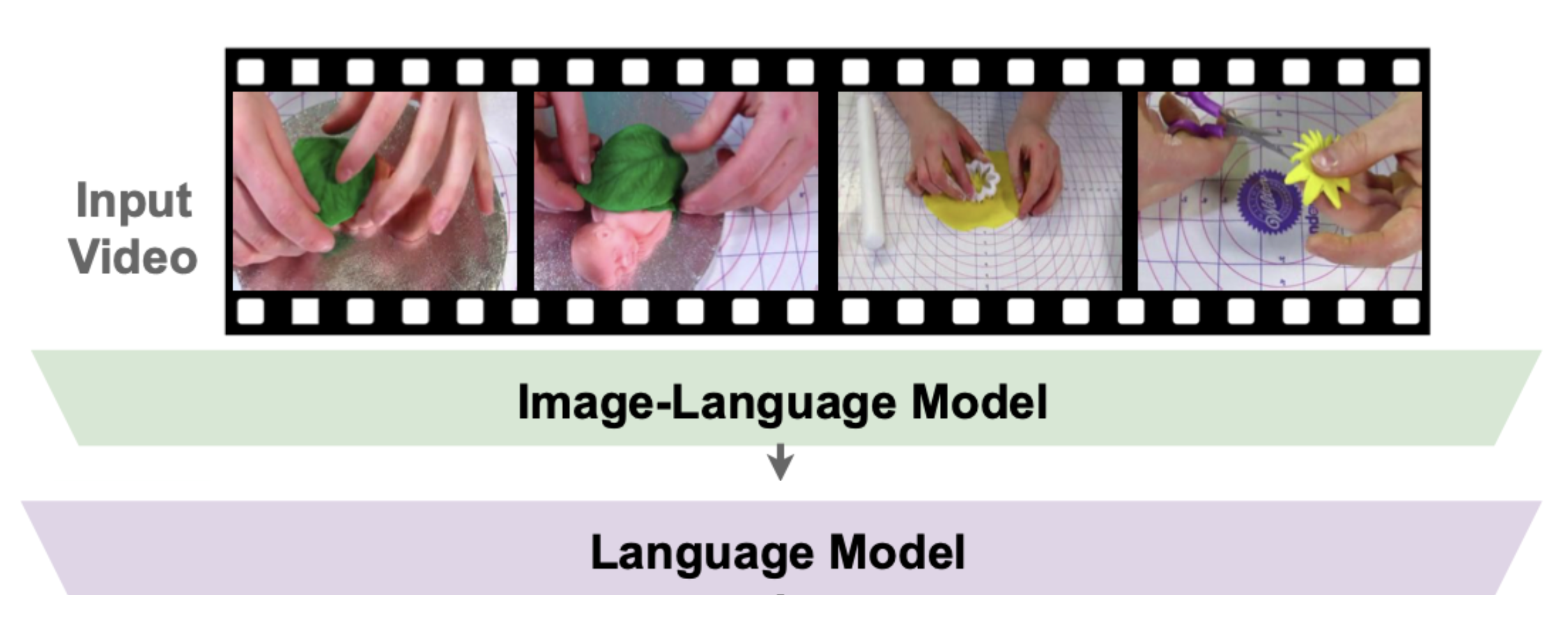
ENACT: Evaluating Embodied Cognition with World Modeling of Egocentric Interaction [Website][PDF][Code][Data] [tl;dr]
Qineng Wang*, Wenlong Huang*, Yu Zhou, Hang Yin, Tianwei Bao, Jianwen Lyu, Weiyu Liu, Ruohan Zhang, Jiajun Wu, Li Fei-Fei, Manling Li
ICLR 2026
Outstanding Paper Award at ICLR 2026 Workshop on World Models
Outstanding Paper Award at ICLR 2026 Workshop on Lifelong Agents
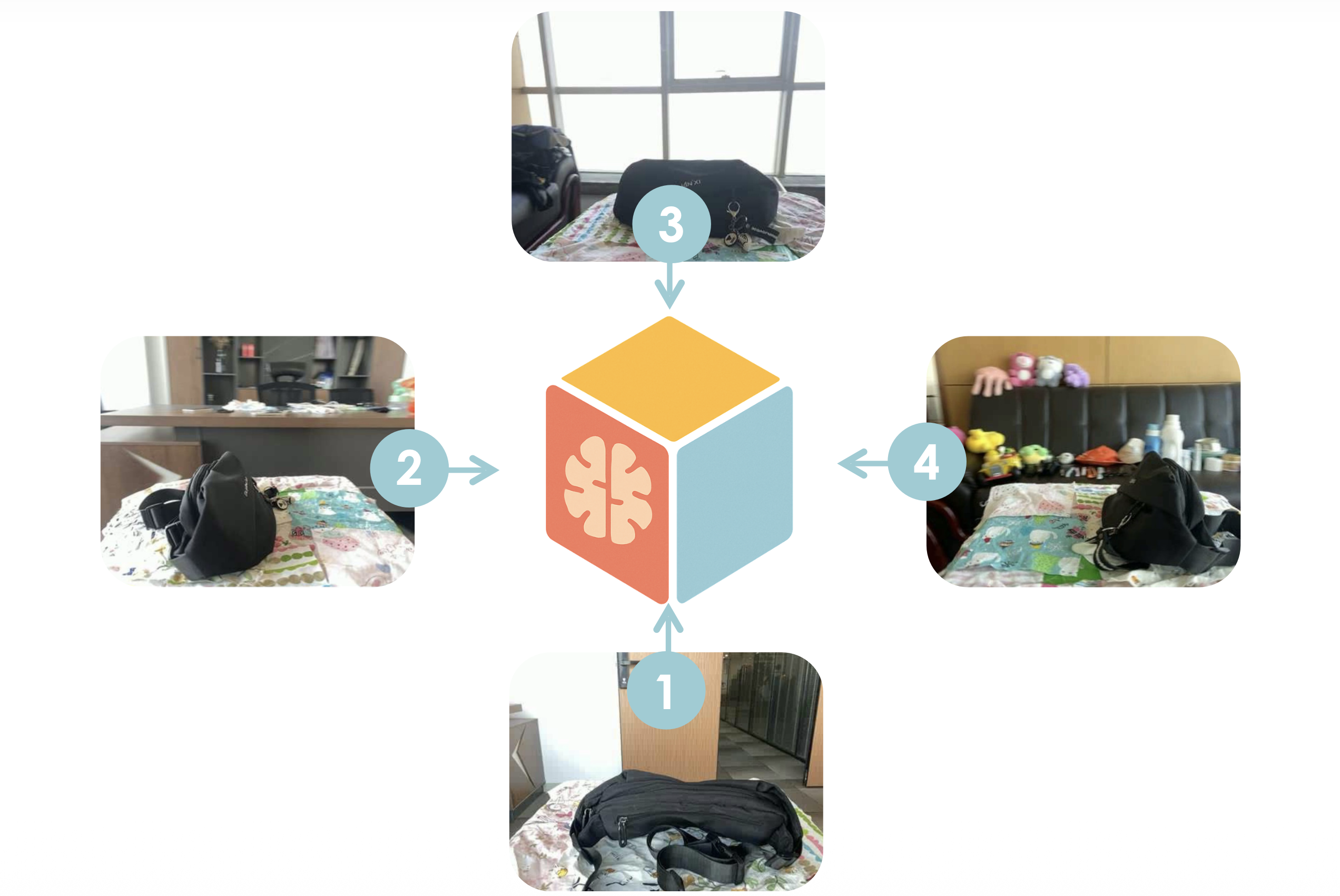
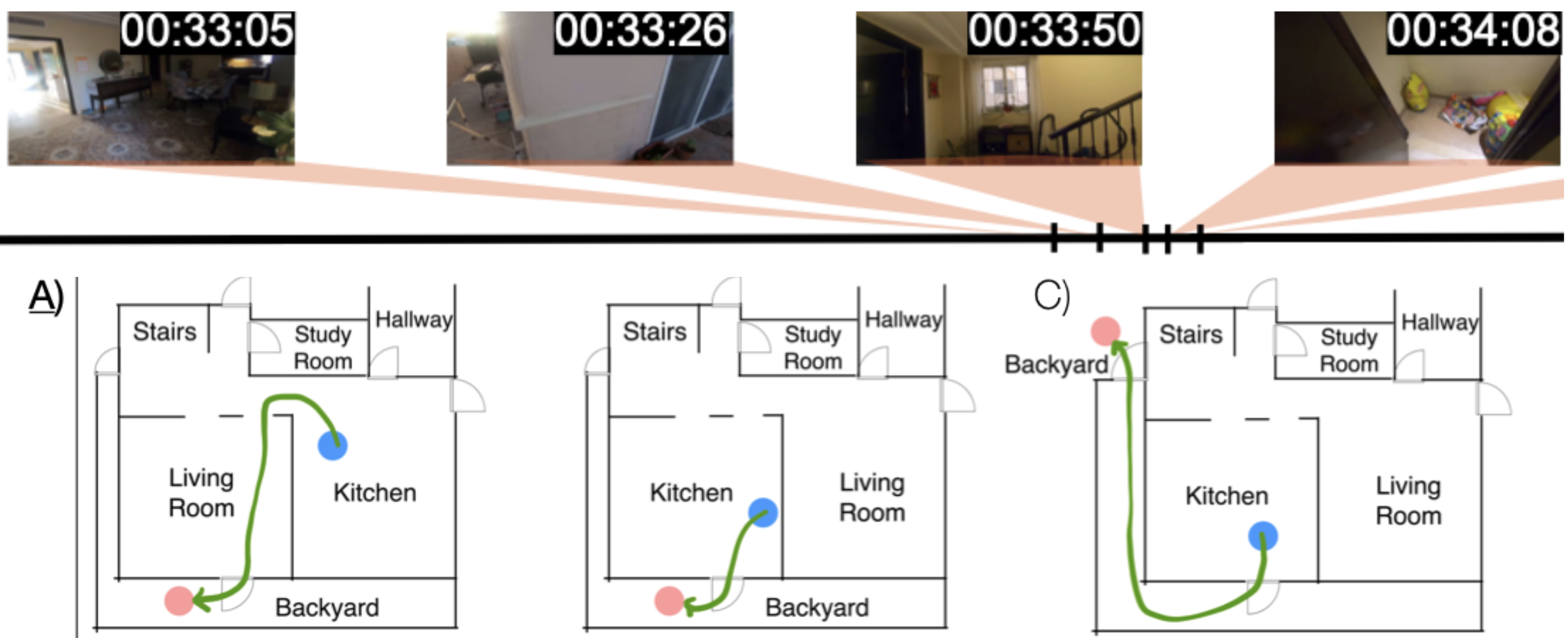
Spatial Mental Modeling from Limited Views [Website][PDF][Data][Code][tl;dr]
Qineng Wang*, Baiqiao Yin*, Pingyue Zhang, Jianshu Zhang, Kangrui Wang, Zihan Wang, Jieyu Zhang, Keshigeyan Chandrasegaran, Han Liu, Ranjay Krishna, Saining Xie, Jiajun Wu+, Li Fei-Fei+, Manling Li+
ICLR 2026
Best Paper Award at ICCV 2025 Workshop on Structural Priors for Vision
Best Paper Honorable Mention at NeurIPS 2025 Workshop on Language Agents and World Models (LAW)
The Best of ICCV 2025, featured by Voxel 51

ActionEQA: Action Interface for Embodied Question Answering [PDF]
Tianwei Bao, Qineng Wang, Kangrui Wang, Mingkai Deng, Guangyi Liu, Jiayuan Mao, Lawrence Birnbaum, Zhiting Hu, Eric P. Xing, Zhaoran Wang, Manling Li
TMLR 2026
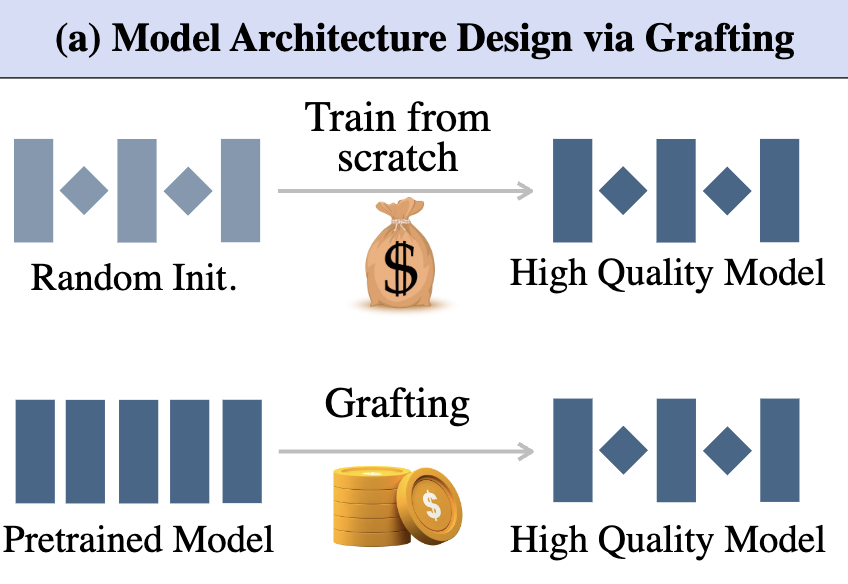
Exploring Diffusion Transformer Designs via Grafting [Website][PDF][Blog][Code][tl;dr]
Keshigeyan Chandrasegaran*, Michael Poli*, Daniel Y. Fu, Dongjun Kim, Lea M. Hadzic, Manling Li, Agrim Gupta, Stefano Massaroli, Azalia Mirhoseini, Juan Carlos Niebles, Stefano Ermon, Li Fei-Fei
NeurIPS 2025 (Oral, Top 0.36%)

EmbodiedBench: Comprehensive Benchmarking Multi-modal Large Language Models for Vision-Driven Embodied Agents [Website][PDF][Code][tl;dr]
Rui Yang, Hanyang Chen, Junyu Zhang, Mark Zhao, Cheng Qian, Kangrui Wang, Qineng Wang, Teja Venkat Koripella, Marziyeh Movahedi, Manling Li, Heng Ji, Huan Zhang, Tong Zhang
ICML 2025 (Oral, Top 1%)
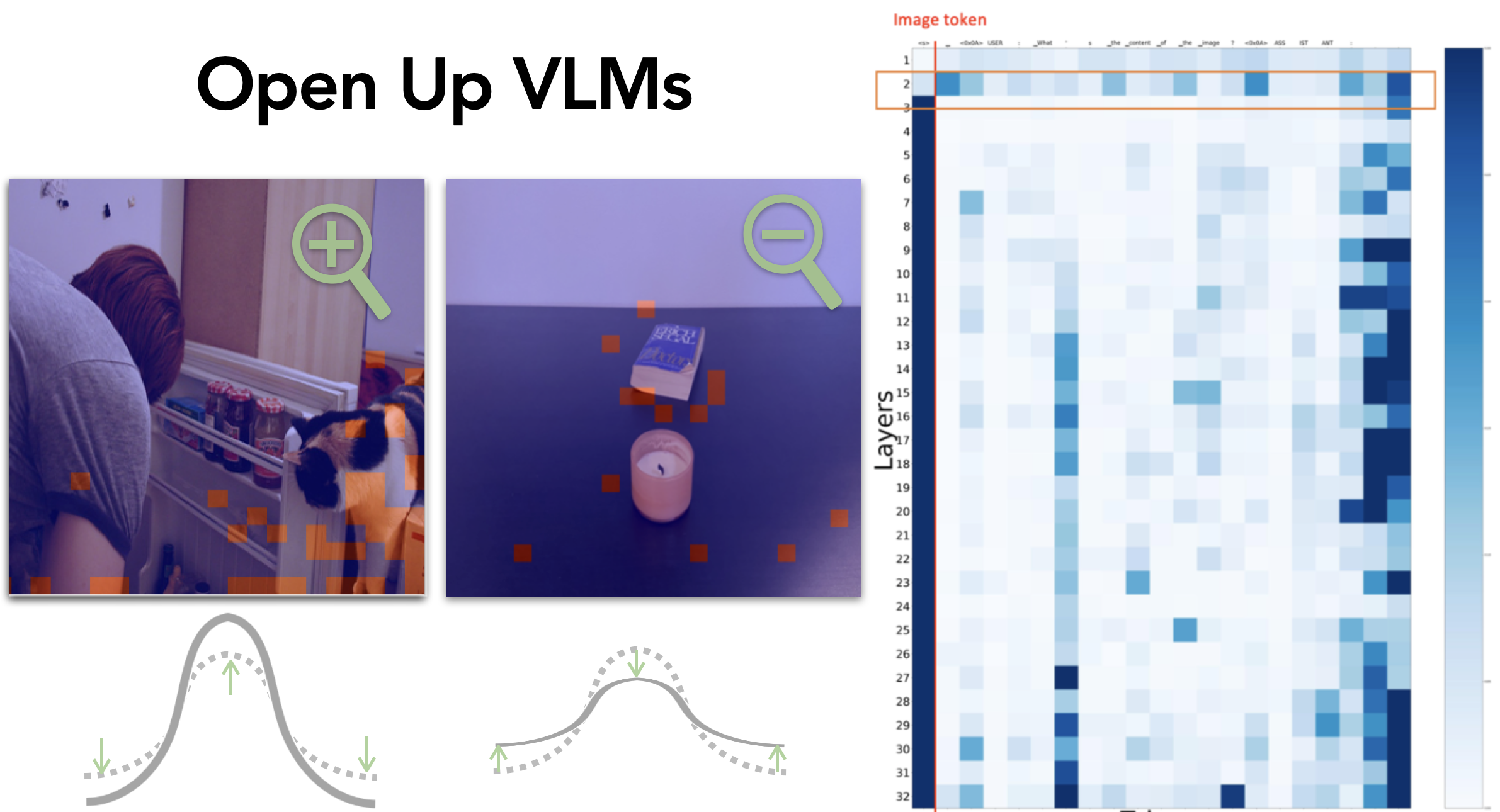
T*: Re-thinking Temporal Search for Long-Form Video Understanding [Website][PDF][Data][Code]
Jinhui Ye*, Zihan Wang*, Haosen Sun, Keshigeyan Chandrasegaran, Zane Durante, Cristobal Eyzaguirre, Yonatan Bisk, Juan Carlos Niebles, Ehsan Adeli, Li Fei-Fei, Jiajun Wu, Manling Li
CVPR 2025, Oral at ICCV 2025 Workshop on Long Multi-Scene Video Foundations
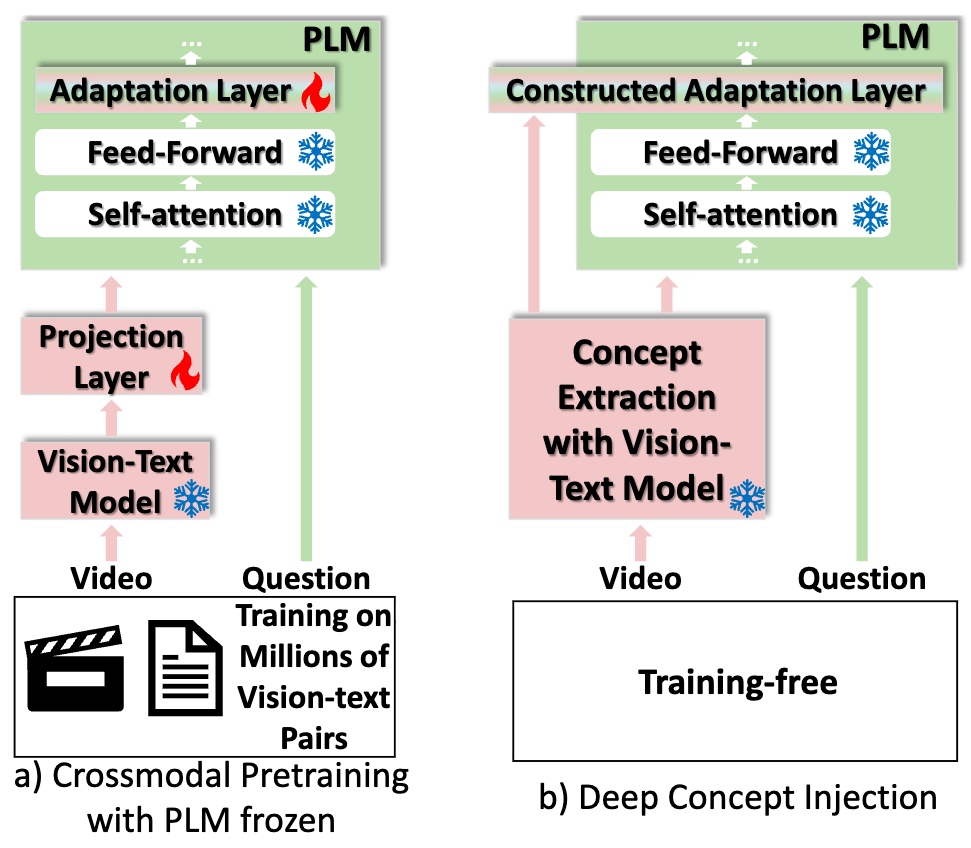
Deep Concept Injection for Zero-shot Multimodal Reasoning [PDF]
Xudong Lin, Manling Li, Richard Zemel, Heng Ji, Shih-Fu Chang
EMNLP 2024

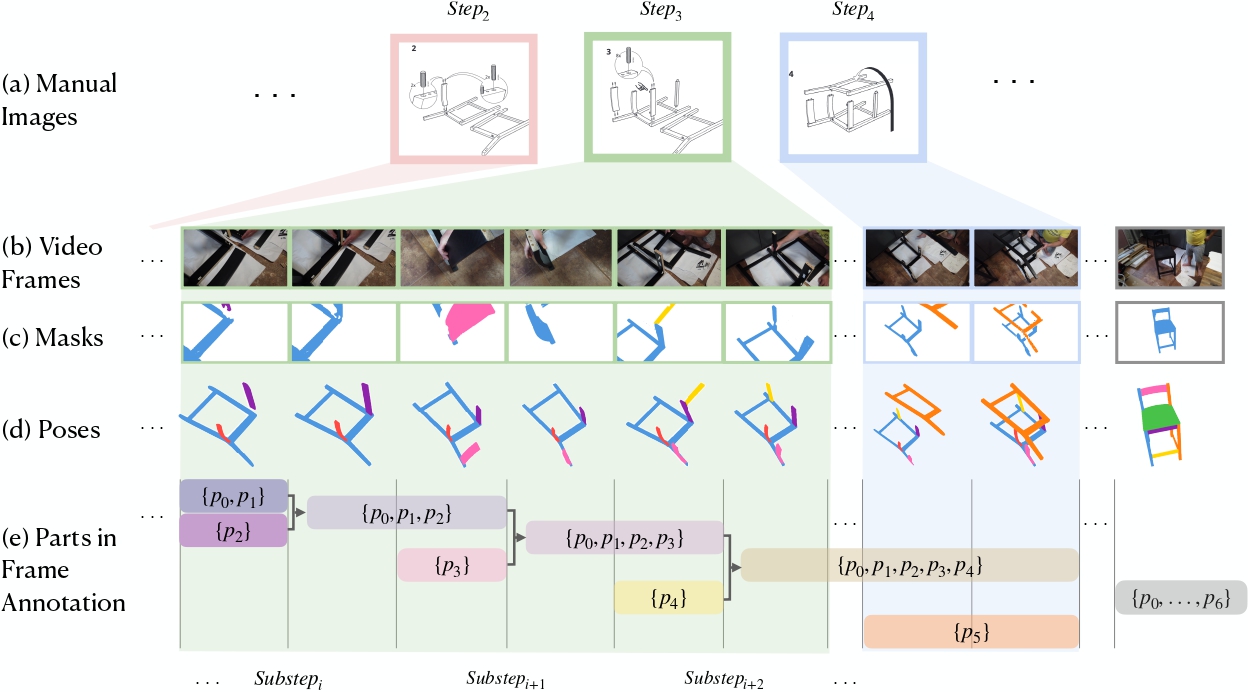
ViStruct: Visual Structural Knowledge Extraction via Curriculum Guided Code-Vision Representation [PDF]
Yangyi Chen, Xingyao Wang, Manling Li, Derek Hoiem, Heng Ji
EMNLP 2023